人機語音交互涉及多項技術任務。首先需要將人聲或聲音轉換為計算機可以分析的數字信號。下一步,將數字信號轉換為詞語。第三步是分析,這其中包括理解句子的結構、語法、語境等。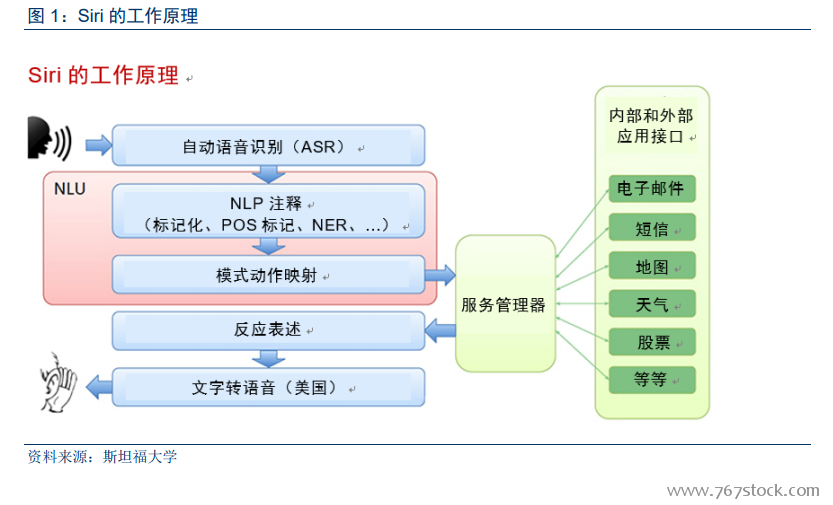
隨著深度學習,機器學習芯片和算法取得突破,ASR、NLP 和 TTS 在過去 5 年中迅速進步。語音識別的單詞錯誤率大幅降低,這主要是由于使用了更高效的聲學模型,運用深度神經網絡(DNN)取代高斯混合模型(GMM,之前多年以來的首選方法)等統計技術。Nuance的研究主管 Nils Lenke 展示數據顯示,在將深度神經網絡算法成功納入語音識別系統后,單詞錯誤率從 2010 年左右開始急劇下降,每年降低約 18%。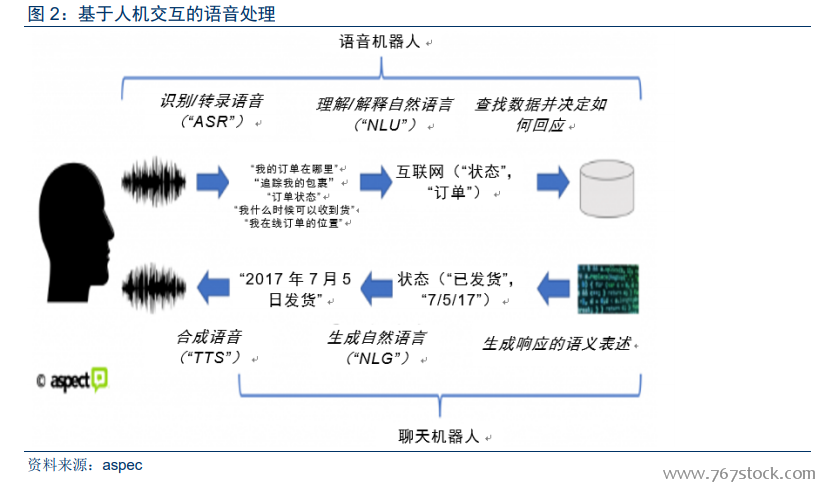
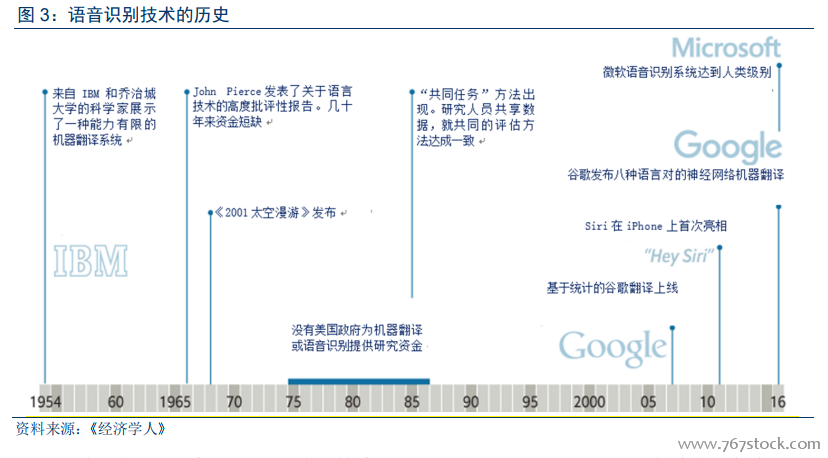
語音識別和自然語言處理是兩個不同的領域。語音識別主要是分析句子、句法(名詞、動詞、形容詞、副詞等)以及結構,即語法(主語動詞、賓語),以便進行轉錄或翻譯。而自然語言處理的重點在于上下文語境和句子的意圖,比如“我想給信用卡還款”,“我如何給信用卡還款”,這兩個句子的分析主要在于理解對象(信用卡)和行動(還款)。但它們最開始的過程是類似的,都要識別聲音模擬頻率,消除背景噪音或多個對話,然后將音頻模擬轉換為數字格式。