AI 芯片按技術架構分類。GPU(Graphics Processing Unit,圖形處理單元):在傳統的馮·諾依曼結構中,CPU 每執行一條指令都需要從存儲器中讀取數據,根據指令對數據進行相應的操作。從這個特點可以看出,CPU 的主要職責并不只是數據運算,還需要執行存儲讀取、指令分析、分支跳轉等命令。深度學習算法通常需要進行海量的數據處理,用 CPU 執行算法時,CPU 將花費大量的時間在數據/指令的讀取分析上,而 CPU的頻率、內存的帶寬等條件又不可能無限制提高,因此限制了處理器的性能。而 GPU 的控制相對簡單,大部分的晶體管可以組成各類專用電路、多條流水線,使得 GPU 的計算速度遠高于 CPU;同時 GPU 擁有了更加強大的浮點運算能力,可以緩解深度學習算法的訓練難題,釋放人工智能的潛能。
我國 AI 芯片發展情況。目前,我國的人工智能芯片行業發展尚處于起步階段。長期以來,中國在 CPU、GPU、DSP 處理器設計上一直處于追趕地位,絕大部分芯片設計企業依靠國外的 IP 核設計芯片,在自主創新上受到了極大的限制。然而,人工智能的興起,無疑為中國在處理器領域實現彎道超車提供了絕佳的機遇。人工智能領域的應用目前還處于面向行業應用階段,生態上尚未形成壟斷,國產處理器廠商與國外競爭對手在人工智能這一全新賽場上處在同一起跑線上,因此,基于新興技術和應用市場,中國在建立人工智能生態圈方面將大有可為。
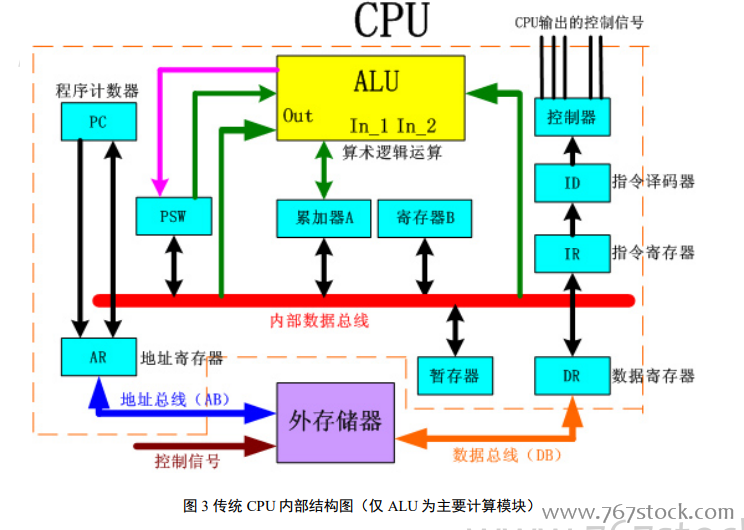
傳統的 CPU 及其局限性。計算機工業從 1960 年代早期開始使用 CPU 這個術語。迄今為止,CPU 從形態、設計到實現都已發生了巨大的變化,但是其基本工作原理卻一直沒有大的改變。通常 CPU 由控制器和運算器這兩個主要部件組成。傳統的 CPU 內部結構圖如圖 3 所示,從圖中我們可以看到:實質上僅單獨的 ALU 模塊(邏輯運算單元)是用來完成數據計算的,其他各個模塊的存在都是為了保證指令能夠一條接一條的有序執行。這種通用性結構對于傳統的編程計算模式非常適合,同時可以通過提升 CPU 主頻(提升單位時間內執行指令的條數)來提升計算速度。但對于深度學習中的并不需要太多的程序指令、卻需要海量數據運算的計算需求,這種結構就顯得有些力不從心。尤其是在功耗限制下,無法通過無限制的提升 CPU 和內存的工作頻率來加快指令執行速度,這種情況導致 CPU 系統的發展遇到不可逾越的瓶頸。