
語音識別、計算機視覺領域取得重大進展。在20世紀50年代到70年代初,人工智能的研究尚處于“推理期”,人們認為如果賦予機器邏輯推理能力,機器就能具有智能。到了20世紀70年代,人們意識到人類之所以能夠判斷、決策,除了推理能力之外,還需要具備一定的知識。發展到20世紀80年代,機器學習真正成為一個獨立的學科領域,相關技術層出不窮。2010年后,“人工智能”相繼在語音識別、計算機視覺領域取得重大進展,圍繞語音、圖像等人工智能技術的創業大量涌現。
虛擬語音助手是人工智能的重要應用領域。計算機視覺、智能語音和機器學習是人工智能的三大核心基礎技術,目前研發出的人工智能應用大多是這三種技術綜合運用的結果,只是其中的主次之分不同。依據核心基礎技術類目,可以將人工智能分為兩大類,即感官智能和決策智能,其中視覺智能、語音智能和深度學習智能是感官智能和決策智能下的三大子賽道。目前,語音智能的一個重要行業應用就是虛擬助手,即“智能語音助手”。它的核心在于人類通過純語音信息實現與機器的交互,讓智能機器“助手”幫忙完成指派的任務。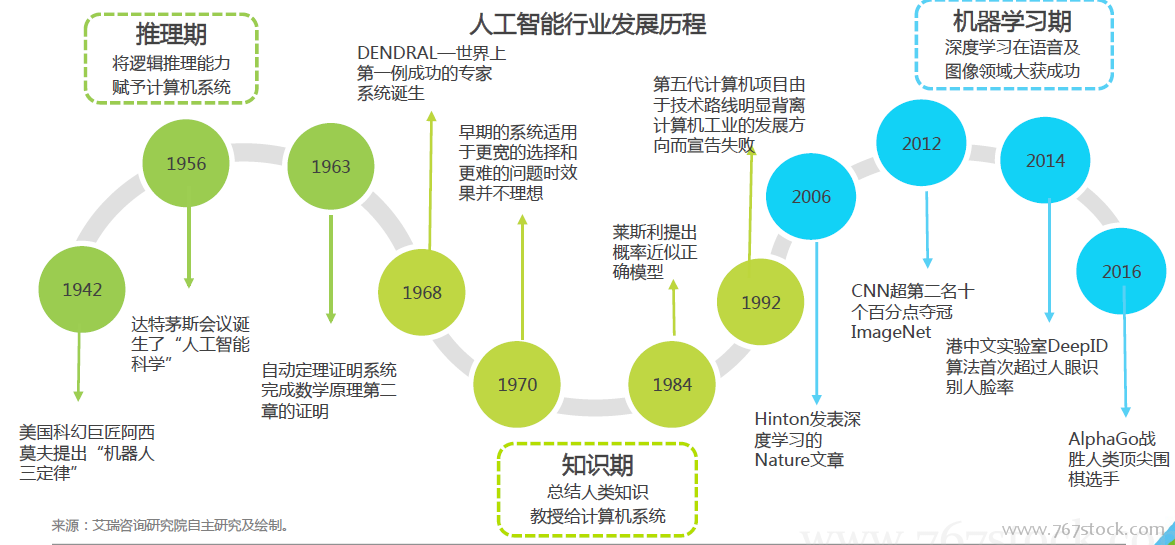
互聯網巨頭紛紛進入布局。從2010年開始,互聯網巨頭們紛紛通過自主研發或并購/參股的方式開始探索智能語音產業,其中,智能語音虛擬助手成為重點布局對象,此外,為占據一定的市場先機,蘋果、谷歌、微軟、亞馬遜、百度、騰訊、搜狗等巨頭們也陸續開始在智能車載、智能家居、智能醫療、可穿戴設備等諸多細分市場尋求突破。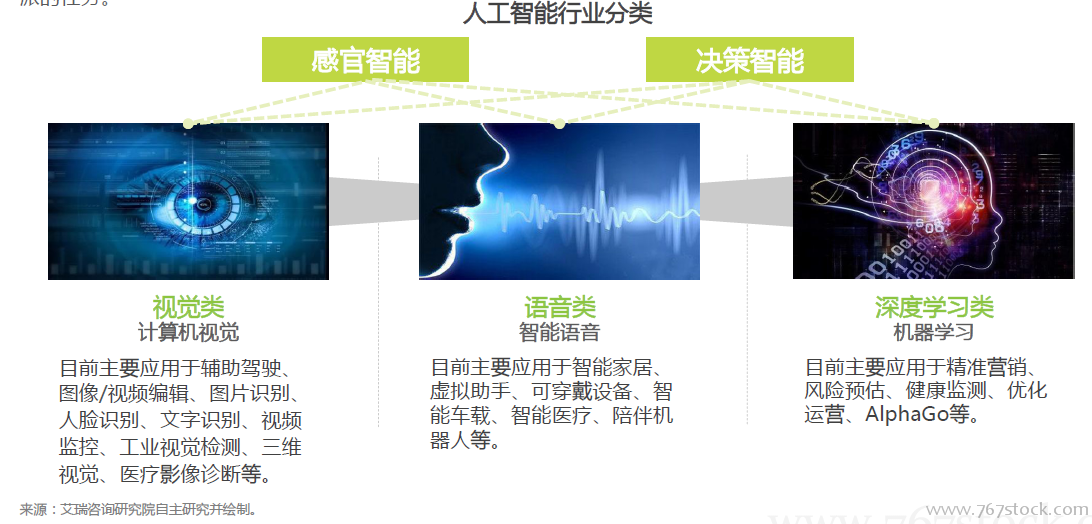
語音識別、聲紋識別、語音合成等。人類因為具有語言的能力而區別于其他物種,智能語音技術即研究人與計算機直接以自然語言的方式進行有效的溝通的各種理論和方法,涉及機器翻譯、閱讀理解、對話問答等,因為語言在詞法、句法、語義等不同層面的不確定性及數據資源的有限性、背景知識的復雜性等各方面限制,智能語音技術仍有非常大的提升空間,僅在特定領域可取得較好的應用,魯棒性存在大量挑戰。在自然語言處理之前,聲紋識別可根據說話人的聲紋特征識別出說話人,語音識別技術可賦予機器感知能力(在深度學習的驅動下,目前近場語音識別準確率可達98%,遠場、抗噪、多人等非限定或配合條件下的識別有待改進),將聲音轉為文字供機器處理,在機器生成語言之后,語音合成技術可將語言轉化為聲音,形成完整的自然人機語音交互,這樣的語音交互系統可看作一個虛擬對話機器人,具體流程如下。
四大板塊協同作業。智能語音產業鏈分為基礎研究機構、語義數據提供商、語音技術提供商及智能語音應用提供商四大板塊。其中,基礎研究機構包括語音合成、語音識別、聲紋識別等基礎技術的研發和技術輸出;語義數據提供商為算法研究和技術輸出機構提供語音、語義數據庫及定制化的數據采集和處理;語音技術提供商將基礎技術轉化為軟件或行業整體解決方案,提供嵌入式或平臺是的語音軟件服務、行業智能語音系統整體解決方案;智能語音應用提供商則有智能移動設備、智能車載設備、智能家居等智能終端廠商,以及輸入娛樂等各類APP或軟件客戶端等。

