
語音交互為本能表達,帶來全新體驗。早期的人機交互主要利用鍵盤,如打字機和DOS 系統的電腦。隨著鼠標的發明和可視化圖形界面的普及,人機交互迎來了第一次重大創新。隨后觸摸屏的普及以及多點觸控的出現,令人機交互進入了二維層面。相比鼠標和鍵盤,多點觸控能更方便、多樣的實現輸入。但是至于此,人機交互依然沒有脫離手動的信息輸入,在人機分離下無法實現互動,語音交互的出現將使這一問題得到解決。
信息密度高,自然且普適。語言是人類與生俱來的一種能力,從學習成本角度而言顯著低于其他手段,語音交互天然適合人類。從普及度而言,幾乎人人都會用語言進行溝通,但是在全球范圍內依舊有許多不會書寫文字的人。假設語音交互能夠普及,在理想狀態下人人都可以用語音命令操控智能設備,實現智能體驗。
解放雙手,更少的感官占用。除了高效的信息溝通外,語音交互可解放雙手、眼睛,不需要與設備接觸即可溝通,使得我們能夠實現一心多用和在特定情況下精力集中。諸如在處于駕駛狀態時,我們就可以通過語音助手來查看智能手機上的信息,從而避免視覺查看而導致的注意力不集中。根據Statista 的調研數據顯示,2016 年美國用戶使用智能語音識別主要原因中,雙手和眼睛被占用為首要理由,占比達60%。可見智能語音識別對于提升用戶便利性有很大的幫助。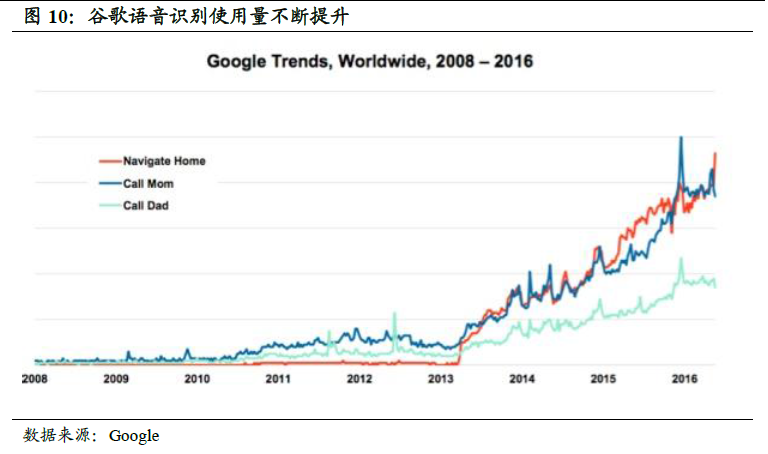
各類語音交互軟件不斷面世。近期三星發布了其語言識別助手Bixby,正式用于S8 系列、Note8 手機。事實上,從產品推出的時間順序來說,三星Bixby 還只能算作是智能語音交互領域的一位新玩家。在Bixby 之前,就已經有了諸如蘋果Siri、微軟Cortana、谷歌Google Assistant、亞馬遜Alexa 等在內的多款智能語音助手被業界熟知。
AI 技術提升語音識別準確度。在提升語音識別的準確度上,過去主要依靠算法的進步和樣本的積累,隨著深度學習算法的出現,語音識別的準確率有了明顯的進步。深度神經網絡算法可以把連續多幀的語音特征并在一起,構成一個高維特征,最終的深度神經網絡可以采用高維特征訓練來模擬。由于深度神經網絡采用模擬人腦的多層結果,可以逐級地進行信息特征抽取,最終形成適合模式分類的較理想特征。

