
AlphaGo Zero 打敗之前所有版本,“左右互搏,天下無雙”!10 月18 日GoogleDeepMind 在《Nature》發表了最新版本的AlphaGo Zero 的論文。AlphaGo Zero在進行了3天的自我訓練后,在100 局比賽中以100:0擊敗了上一版本的 AlphaGo——而上一版本的 AlphaGo Lee 擊敗了曾18 次獲得圍棋世界冠軍的韓國九段棋士李世乭。經過 40 天的自我訓練后,AlphaGo Zero 變得更加強大,超越了?Master?版本的 AlphaGo——Master 曾擊敗世界上最優秀的棋士、世界第一的柯潔。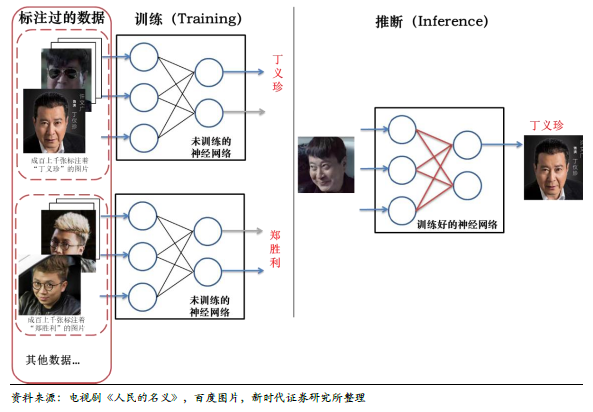

機器學習可分類為監督學習、非監督學習、強化學習,如何簡單理解?下面三圖以電視劇《人民的名義》為例,通俗介紹了監督學習(當前最火熱、應用范圍最大)、非監督學習、強化學習分別是什么。監督學習是當前使用最多的模型,需要有標注的數據錄入模型,對模型訓練(優化模型的參數),訓練的后的模型可以就進行推斷了(即應用)。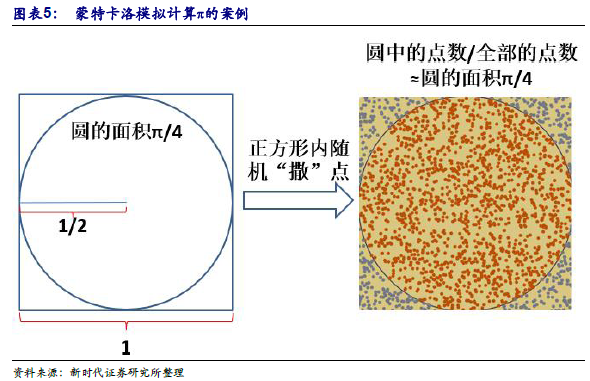
蒙特卡洛(Monte Calro)模擬是用大量隨機樣本解決數值的方法——采樣越多,越接近最優解。蒙特卡洛模擬通過大量隨機樣本解決數值問題,是一類方法的統稱,誕生于上個世紀40 年代美國的”曼哈頓計劃”,名字來源于賭城蒙特卡羅,象征概率。簡單的案例為計算圓周率π的概率:在一個1×1 的正方形(內臵一個半徑1/2 的圓)內撒點,如果點數足夠大且均勻分布,那么圓的面積近似于圓中點數/全部點數,由此可計算出圓周率π。

