人工智能基礎數據服務意指為AI算法訓練及優化提供數據采集和標注等形式的服務。人工智能基礎數據服務指為AI算法訓練及優化提供的數據采集、清洗、信息抽取、標注等服務,以采集和標注為主。人工智能概念爆發伊始,算法、算力、數據就作為最重要的三要素被人們樂道,進入落地階段,智能交互、人臉識別、無人駕駛等應用成為了最大的熱門,AI公司開始比拼技術與產業的結合能力,而數據作為AI算法的“燃料”,是實現這一能力的必要條件,因此,為機器學習算法訓練、優化提供數據采集、標注等服務的人工智能基礎數據服務成為了這一人工智能熱潮中必不可少的一環。如果說計算機工程師是AI的老師,那基礎數據服務就是老師手中的教材。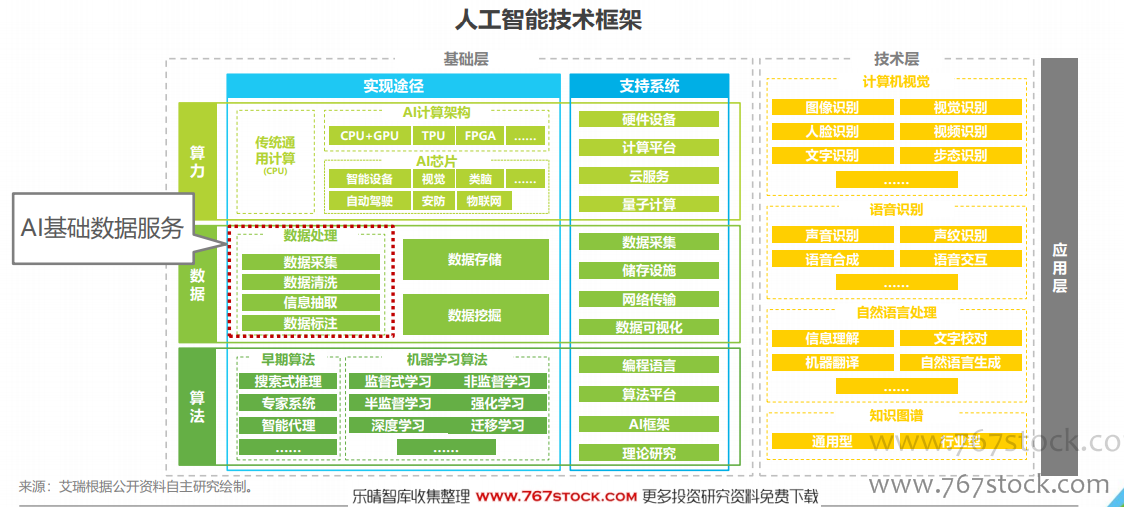
行業進入成長期,行業格局逐漸清晰。伴隨國內人工智能熱潮爆發,大量的AI公司拿到融資,為了不斷提高算法精度,數據采標需求也空前爆發,一度催生了行業的繁榮。但早期的AI基礎數據服務門檻較低,玩家魚龍混雜,使行業標準模糊、服務質量參差不齊。隨著競爭加快,AI公司對訓練數據的質量要求也不斷提高,并且當產業落地成為主旋律,需求方對垂直場景的定制化數據采標需求成為主流,眾多小型AI基礎數據服務公司從數據質量和采標能力上達不到要求,或被淘汰,或依附大平臺,行業格局逐漸清晰,頭部公司實力逐漸凸顯。隨著算法需求越來越旺盛,目前機器輔助標注、人工主要標注的手段需要改進提升,增強數據處理平臺持續學習和自學習能力,增加機器能夠標注維度、提升機器處理數據的精度,由機器承擔主要標注工作將成為下一階段的行業重心。未來,越來越多的長尾、小概率事件所產生的數據需求增強,人機協作標注的模式性價比不足,機器模擬或機器生成數據會是解決這一問題的良好途徑,及早研發相應技術也將成為AI基礎數據服務商未來的護城河。
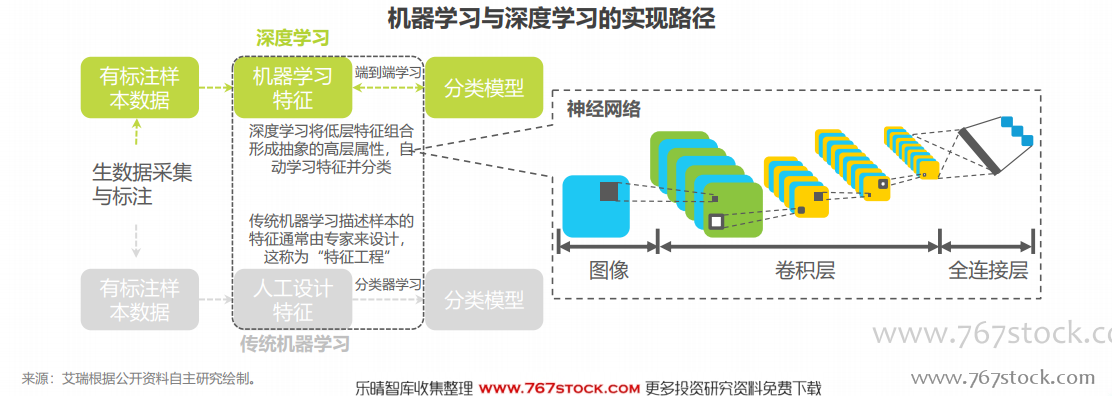
目前有監督的深度學習是主流,標注數據是其學習根本。人工智能是研究如何通過機器來模擬人類認知能力的科學,機器學習是現階段實現人工智能的主要手段。機器學習方法通常是從已知數據中學習規律或者判斷規則,建立預測模型,其中,深度學習可以通過對低層特征的組合,形成更加抽象的高層屬性類別,自動從信息中學習有效的特征并進行分類,而無需人為選取特征。憑借自動提取特征、神經網絡結構、端到端學習等優勢,深度學習在圖像和語音領域學習效果最佳,是當今最熱門的算法架構。在實際應用中,深度學習算法多采用有監督學習模式,即需要標注數據對學習結果進行反饋,在大量數據訓練下,算法錯誤率能大大降低。現在的人臉識別、自動駕駛、語音交互等應用都采用這類方法訓練,對于各類標注數據有著海量需求,可以說數據資源決定了當今人工智能的高度。由于應用有監督學習的AI算法對于標注數據的需求遠大于現有的標注效率和投入預算,無監督或僅需要少量標注數據的弱監督學習、小樣本學習成為了科學家探索的方向,但目前無論從學習效果和使用邊界來看,均不能有效替代有監督學習,人工智能基礎數據服務將持續釋放其對于人工智能的基礎支撐價值。